
Pourquoi un test coute-t-il cher à maintenir ?
Un test de non-régression passe — et est généralement affiché en vert — ou bien il échoue — et il est alors généralement affiché en rouge.


Un test de non-régression passe — et est généralement affiché en vert — ou bien il échoue — et il est alors généralement affiché en rouge.
Lorsque le test passe, c’est que tout s’est passé comme prévu : le comportement actuel correspond au comportement attendu, celui qui a été spécifié dans le test.
À l’inverse, lorsque le test échoue, c’est que quelque chose ne s’est pas passé comme prévu. Voyons en revue les différents cas de figure qui mènent à un test en échec.
Nous allons voir que la réalité n’est pas aussi binaire que “le test passe ou échoue”. En effet, il faut prendre en compte toute la complexité de mise en place et d’exécution dudit test : il est toujours possible de mal implanter le test et qu’il retourne un mauvais résultat. On parlera par exemple de faux positif pour un test qui passe alors qu’il devrait échouer et de faux négatif pour un test qui échoue alors qu’il devrait passer.
Ces notions sont importantes à maîtriser car elles sont à la base de la logique d’une stratégie de test Agile.
Pourquoi un test de non-régression échoue-t-il ?
Voici les raisons possibles d’un test de non-régression en échec :
Le test a rattrapé une régression
Le test met en valeur un impact non-anticipé
Il y a une erreur dans l’écriture du test ou dans l’outillage de test
Le test a rattrapé une régression
C’est le cas qui motive l’existence même du test de non-régression : pour rattraper des régressions.
Cet échec du test justifie par ailleurs que c’est un bon test : il sert à quelque chose. On pourrait questionner la pertinence d’un test qui n’attraperait jamais aucune régression. Serait-il utile ?
Sur ce sujet, on peut citer Google qui a justement essayé d’utiliser les statistiques d’échec d’un test pour définir la pertinence du test et en tenir compte dans la stratégie d’exécution de tests de l’intégration continue. (lien à la fin de l’article)
Le test met en valeur un impact non-anticipé
Un test peut échouer sans pour autant que cela soit à proprement parler la détection d’une régression. Il arrive que tous les impacts d’un changements n’ait pas été complètement anticipés.
Mise à jour partielle des tests
Voici un premier exemple plutôt simple pour illustrer ce cas de figure :
Dans le cadre d’un système de facturation et de comptabilité, le taux de TVA est mis à jour.
Le développeur en charge du changement a bien pensé à mettre à jour les tests de la génération des factures. Il a par contre oublié de mettre à jour les tests de remboursement de la TVA sur les achats de l’entreprise.
Suite au changement, les tests de la génération des factures passent mais les tests de remboursement de la TVA échouent.
Le développeur se rend compte de la raison de l’échec des tests de remboursement de la TVA et les met à jour avec le nouveau taux de TVA.
Mise à jour du comportement produit
Il arrive aussi que le changement soit plus profond, qu’il ne s’agisse pas juste d’un oubli de tests à mettre à jour, mais véritablement d’impacts non-anticipés sur le produit.
Voici un autre exemple pour illustrer ce cas de figure :
Dans le cadre du logiciel d’une box de télévision, la fonctionnalité de “favoris” est mise à jour pour y intégrer automatiquement toutes les vidéos que l’utilisateur a commencé à regarder.
La demande de cette évolution précise clairement les critères selon lesquels une vidéo est ajoutée ou non aux favoris, en fonction du temps de lecture, de s’il s’agit d’un film ou d’une série, et ainsi de suite.
Cependant, rien n’est précisé à propos des vidéos -18, réservées aux adultes. Le système actuel interdit complètement la mise en favori de telles vidéos en ne proposant pas le bouton favori. En effet, l’espace des favoris n’est pas vérouillé par le code parental et y faire remonter ces vidéos poserait problème.
Que faire alors lorsque l’utilisateur regarde une vidéo -18 réservée aux adultes ? Faut-il automatiquement l’ajouter aux favoris tel que spécifié ?
Si la réponse est évidente pour un spécialiste du domaine, il ne l’est pas pour un développeur qui n’a jamais baigné dans le milieu.
Dans ce cas de figure, la réponse à apporter aux tests en échec n’est pas évidente, étant donné que le comportement du produit a changé en profondeur. Que faut-il faire ?
Considérer les tests en échec comme des régressions ? Auquel cas il faut mettre à jour le code testé
Ou alors définir le nouveau comportement attendu ? Auquel cas il faut mettre à jour les tests
Cette situation est d’autant plus périlleuse que ce n’est pas forcément le développeur qui a la réponse. C’est exactement dans ces situations-là que les spécifications exécutables rédigées en langage pseudo-naturel avec le vocabulaire métier apportent le plus de valeur. Il est alors possible de solliciter facilement les non-développeurs pour répondre à cette question :
Est-ce une régression ou un changement non-anticipé du fonctionnel du produit ?
Il y a une erreur dans l’écriture du test ou dans l’outillage de test
Dernier cas de figure d’un test en échec, l’erreur n’est ni dans le code du produit ni dans la définition du fonctionnel du produit, mais dans l’implantation même du test ou dans son outillage.
Le test plante
Cela peut se manifester de manière assez directe via un plantage du test. Les frameworks de test unitaire, par exemple, intègrent généralement ce cas de figure en donnant trois status possibles pour un test :
Test en succès : le comportement constaté correspond au comportement attendu
Test en échec : le comportement constaté diffère du comportement attendu
Test en erreur : l’exécution du test a cassé l’exécuteur de test, ou a levé une exception qui n’a pas été rattrapée par le test
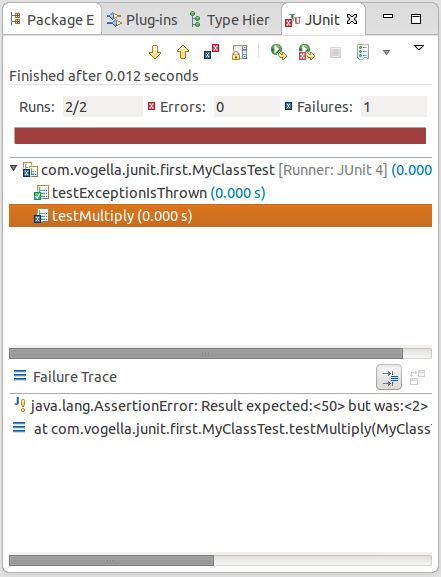

Lorsqu’un test plante, on n’a pas de status à donner sur le produit qui est testé : on ne sait pas si le code fonctionne ou pas comme attendu.
L’erreur peut tout aussi bien être dûe à des changements dans l’outillage de test, que dans le produit lui-même. Qui plus est, l’erreur peut être dûe à des changements dans le produit lui-même sans pour autant être visible en environnement réel, car ne se produisant qu’en environnement de test.
Pour résumer la situation : tout ce que l’on sait, c’est qu’il y a un problème et qu’il va falloir investiguer…
L’écriture ou l’outillage du test est approximative

Le test, ou tout l’outillage de test qui le supporte, a peut-être été écrit de manière approximative. Par exemple :
Non- respect des bonnes pratiques de codage
Non-respect des bonnes pratiques de test
Mauvaise gestion de l’asynchronisme
Environnement non ou mal nettoyé après chaque test
Environnement de test non fiable
Dépendance envers des services externes aléatoires
…
Souvent, cela va se traduire par des tests aléatoires, dont le résultat n’est pas fiable d’une exécution à une autre.
Lorsque ce cas de figure arrive, une première investigation arrive à la conclusion suivante :
L’énoncé du test est le bon ; le fonctionnel n’a pas changé. Le code testé satisfait au test ; il n’y a pas de régression. De temps en temps le test échoue, mais on ne sait pas pourquoi… 😫

Pour résumer la situation : tout ce que l’on sait, c’est qu’il y a un problème et qu’il va falloir investiguer… (et que ça va être long et douloureux)
Constat
Lorsqu’un test de non-régression échoue, on est la plupart du temps face à une régression et tout est dans le meilleur des mondes :
Grâce au filet de non-régression automatisé, on évite le drame
Le test fonctionne comme il devrait fonctionner, rien n’est à retoucher côté test

Malheureusement, il n’est pas toujours aussi évident de définir la raison de l’échec du test de non-régression. Cela nécessite alors une investigation longue et coûteuse.
Avec une bonne stratégie de test, ce cas de figure sera exceptionnel.
Avec une approche approximative du test, ce cas de figure sera très fréquent.
De la redondance des tests comme fondement d’une stratégie de test automatisée
Avez-vous déjà entendu cette phrase ?
Si je valide toute l’application avec ce test de bout en bout, je n’ai pas besoin de refaire des tests de chacun des éléments de l’application. Pas vrai ? De toutes façons, je teste indirectement toutes ces subtilités via mon test de bout en bout.
Cette manière de penser, cette idée reçue est fondamentalement erronée. Elle est même à l’opposé d’une bonne stratégie de test automatisée.
L’élément clé à prendre en compte est bien le cout de maintenance des tests.
Le cout de maintenance comprend bien entendu la mise à jour de frameworks et autres outillages, ou encore un refactoring permanent pour garder le code de test en bonne santé.
Mais le cout de maintenance d’un test comprend aussi le cout de faire les investigations lorsque le test échoue pour définir s’il s’agit d’une régression, d’un impact fonctionnel non-anticipé, ou d’un problème d’outillage de test.
Réduire le cout d’investigation d’un test en échec
Comment réduire le cout d’investigation d’un test en échec ?
Tout d’abord en suivant les bonnes pratiques de codage et de test. Mais aussi en construisant plusieurs ensemble de tests complémentaires.
Ces tests pourraient sembler redondants, puisque “ils testent la même chose plusieurs fois.” Or c’est justement cette redondance qui va permettre de déterminer rapidement la raison d’un test en échec.
Concrètement, lorsqu’un test de haut niveau échoue, le résultat des autres tests de plus bas niveau fournissent un premier niveau d’information qui permet d’investiguer rapidement la cause de l’échec.
Un certain niveau de redondance dans les tests est donc bénéfique.
La pyramide de test
Ce point de vue sur la redondance dans les différents tests d’une stratégie d’automatisation des tests fait directement appel à la pyramide des tests de Mike Cohn. (lien à la fin de l’article)

Voici une autre manière de lire la métaphore de la pyramide de test :
Inutile de mettre en place des tests de haut niveau si les tests de bas niveau n’existent pas déjà : le cout d’investigation des tests de haut niveau risquerait d’exploser et donc à terme d’être supprimés
À l’inverse, les tests de bas niveau ne suffisent pas : il faut également vérifier la cohérence globale du système, la redondance entre les tests n’était pas nécessairement un problème à éliminer
Pour aller plus loin
Analyser la fréquence d’échec d’un test pour augmenter la pertinence des suites de test
Efficacy Presubmit
By Peter Spragins with input from John Roane, Collin Johnston, Matt Rodrigues and Dave Chen Originally named "Test…testing.googleblog.com
La pyramide de test de Mike Cohn
bliki: TestPyramid
tags: The test pyramid is a way of thinking about different kinds of automated tests should be used to create a…martinfowler.com
Que pensez-vous de cet article?
J’apprécierais vraiment si vous pouviez me laisser un commentaire pour me dire ce que vous appréciez ou ce qui pourrait être amélioré dans cet article.
Et si vous avez aimé cet article, merci d’applaudir 👏 et de le partager !
À bientôt 😊