
Gestion de risque : formalisation et communication
Quand l’information se perd, c’est tout le process qui menace de s’enrayer

Quand l’information se perd, c’est tout le process qui menace de s’enrayer
This article is also available in English.
Je voudrais conclure mon histoire à propos des mises en production en faisant un focus spécifique sur l’analyse de risque.
Notre recette pour des mises en prod’ quotidiennes
Il était une fois une équipe qui galérait à mettre en prod’…medium.com
Comme précisé dans mon article précédent, nous appliquons une stratégie de gestion de risque pour cibler l’effort de tests de non-régression afin d’éviter de devoir dérouler l’intégralité du plan de test de non-régression.

Voici à quoi ressemble le résultat d’une telle stratégie de gestion de risque :
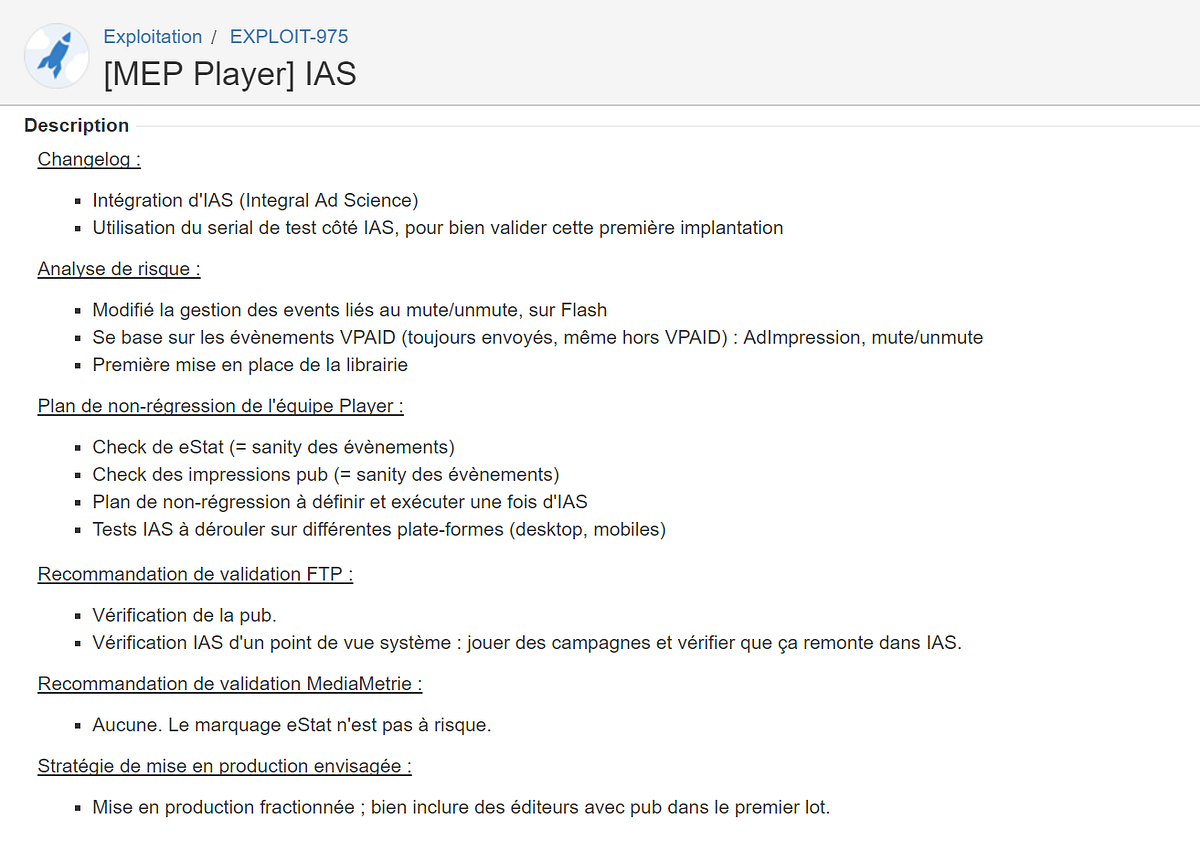
Creusons cette stratégie d’analyse de risque

Cette stratégie de gestion de risque est composée de plusieurs parties :
Le changelog
L’analyse de risque
(Interne à l’équipe) Le plan de test de non-régression
(Externe à l’équipe) La validation par les partenaires
La stratégie de mise en production
Changelog
Qu’est-ce qui a été modifié ?
Le changelog est l’ensemble exhaustif des changements apportés par cette release.
Il était à l’origine rédigé par les développeurs. Par la suite ils ont mis en place une rigueur dans la rédaction des messages de commit GIT et désormais le changelog n’est rien d’autre que le condensé des messages de commit.
Analyse de risque
Qu’est-ce qui peut être potentiellement cassé ou impacté par cet ensemble de changements connus ?
L’analyse de risque requiert une manière de penser particulière, typiquement étrangère aux développeurs.
Si vous posez la question aux développeurs, ils penseront immédiatement à comment valider les changements ce qui tape complètement à côté de la question : ces nouveaux changements sont probablement la partie la mieux testée de l’application à ce moment présent. En effet, en amont de la mise en production, tout le monde a déjà dû tester ces changements dans tous les sens.
Au contraire ce que l’on veut vérifier c’est tout ce qui est autour du changement mais pas directement lié au changement en lui-même. Afin de gérer les impacts.
C’est là l’une des compétences clés des testeurs : effectuer des analyses de risques constitue le cœur de métier des testeurs. Les développeurs peuvent aussi apprendre cette compétence (ce qui fera d’eux de meilleurs développeurs) mais avoir un testeur à disposition dans l’équipe sera un gros avantage. Le binômage (pair-testing) est votre meilleur ami.
Plan de non-régression
Quels sont les tests que nous exécuterons pour gérer les risques que nous avons identifié ?
À nouveau, le but n’est pas de valider les changements mais de s’assurer que les changements n’ont rien cassé.
Le plan de test de non-régression est mis sur pied à partir de l’analyse de risque :
L’ensemble des scenarii de test qui doivent être exécutés pour bien couvrir la zone à risque
L’ensemble des devices/OS/browsers qui doivent être testés, d’un point de vue compatibilité
On peut aussi inclure des sessions de test exploratoire.
Validation par les partenaires
Quelles vérifications recommandons-nous aux partenaires ?
Nous ne travaillons pas en isolation. Nous avons différentes sortes de partenaires :
Nous produisons une librairie qui sera utilisée par des clients internes à l’entreprise
Certains fonctionnalités requièrent une validation formelle par une tierce partie afin de certifier que notre produit respecte bien les spécifications du marché
Certaines fonctionnalités sont sur le chemin critique de la rentrée d’argent, aussi nos partenaires voudront être sûr que l’équipe ne casse rien de lié à ces fonctionnalités
Comment traiter ces partenaires ? Comment les impliquer juste ce qu’il faut ? S’il est impossible de les éviter complètement, on ne veut pas non plus trop les impliquer car cela impacterait négativement la vitesse de l’équipe. En effet, la validation par les partenaires est en général longue et bloquante.
Dans cette section nous proposons un compromis entre une implication totale et une ignorance complète de la part des partenaires. Dans tous les cas, il ne s’agit que d’une recommandation : c’est aux partenaires de décider s’ils veulent la suivre ou non.
Il est essentiel de fournir la totalité de la stratégie de gestion de risque aux partenaires. Sinon ils ne seront pas capables de faire le choix entre suivre ou non nos recommandations. Ce n’est qu’en ayant toute l’information en main qu’ils sont capables de faire un compromis et d’éviter l’option de la non-régression complète.
Stratégie de mise en production
Va-t-on mettre en production incrémentalement ou bien d’un seul coup ? Dans le cas d’une mise en production incrémentale, quelles sont les étapes intermédiaires ?
Enfin, nous proposons une stratégie de mise en production.
Pour l’instant notre outillage n’est pas le plus adapté pour permettre de vrais déploiements progressifs. Aussi il peut arriver que nous préférions éviter les déploiements progressifs pour ménager nos efforts mais aussi pour accélérer notre rythme de mise en production.
Il y a aussi des cas de figure où un déploiement progressif n’aide pas vraiment à détecter rapidement les problèmes.
Enfin il est déjà arrivé que nos partenaires nous demandent explicitement un déploiement progressif en lieu et place de tests de non-régressions de leur côté.

Communication avec l’équipe des exploitants

Hey ! C’est un ticket JIRA.
Oui, en effet. C’est parce que le process actuel de l’équipe d’exploitants est basé sur JIRA. Il semblait judicieux de partager les stratégies de gestion de risque avec l’équipe des exploitants. Et puisque nous cherchions un endroit pour les rédiger et stocker, alors ce ticket JIRA obligatoire était l’endroit logique.
Effet de bord intéressant : en liant l’analyse de risque à la création du ticket JIRA exploitation, nous nous assurions que ce ticket JIRA n’était pas créé au dernier moment. Une situation gagnant-gagnant !
Communication avec nos partenaires
Etant donné que la validation avec nos partenaires peut bloquer notre process, il est essentiel de mettre l’effort nécessaire pour bien gérer ces dépendances.
Pour réduire le risque de blocage, nous leur suggérons quelle validation ils devraient faire. Nous suivons le même mode de fonctionnement basé sur l’analyse de risque. Mais encore plus important, nous partageons tous les éléments qui nous ont menés à cette suggestion.
Si nous ne leur fournissons pas cette information (changelog + analyse de risque + quels tests seront effectués en amont d’eux) alors la seule option qui s’offre à eux est d’effectuer une passe de non-régression complète. Ce que nous essayons d’éviter à tout prix pour continuer d’avancer vite.
Pour éviter le test en boîte noire, il faut ouvrir la boîte.
Communication avec le reste de l’entreprise
Enfin, nous gardons le reste de l’entreprise informé des derniers changements dans le produit.
La vitesse de release de l’équipe rend simplement impossible une communication par e-mail à chaque release. À la place l’équipe a créé une salle spécifique dans le Slack de l’entreprise et y annonce les releases. Comme d’habitude, la totalité de la stratégie de gestion de risque est fournie.
En conclusion…
Faites une véritable analyse de risque mais, encore plus important, partagez-la avec le reste du monde !
Vous ne pouvez tout simplement pas demander aux autres équipes comment ils devraient tester votre produit si vous ne leur dites pas ce que vous avez fait à votre produit.
Une bonne communication est essentielle. Partagez l’information dont vous disposez.
Envie d’aller plus loin ?
Cet article fait partie d’une série sur comment nous avons réussi à faire des mises en production quotidiennes. Pour voir les autres articles :
Notre recette pour des mises en prod’ quotidiennes
Il était une fois une équipe qui galérait à mettre en prod’…medium.com
Cet article vous a plu ?
Abonnez-vous à moi via le bouton Follow pour être notifié des autres articles !
Et n’oubliez pas de m’applaudir 👏 et de partager l’article ! N’oubliez pas que c’est votre amour 💓 qui me fait mettre autant de cœur à l’ouvrage.
Merci 😄